ML-Logistic Regression
之前提到为什么我们不可以把Square error作为损失函数,那是因为,当使用Square error的时候,我们得到的损失函数会是起起伏伏的,因此,会产生许多局部最优解。换句话来讲,就是我们的Cost function此时不是Convex函数(凸函数)。
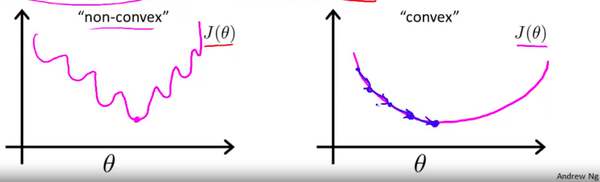
Coursera里,Andrew直接给出了Cost Function,并没有过多的解释为什么会要选择这个函数。然而,在Stanford CS229的笔记里做了详细的阐述,不过它提出的概念与损失函数有些不同,不过大相径庭。在学习的时候,我也针对不同写了小记
下面,我们来推导一下,新的Cost Function是怎么产生的:
首先让我们从概率的角度来构造这个分类模型,假定
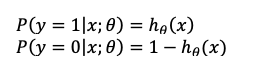
我们可以把两个方程结合成一个方程:
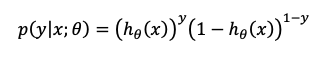
假定我们有n个训练样本而且我们的训练样本彼此之间都是相互独立的$P(A\cap B)=P(A)P(B)$。因此我们可以得到似然函数:
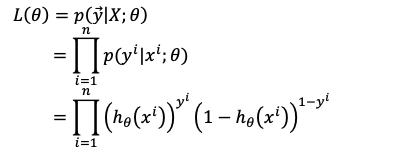
得到了似然函数,那我们的目的是什么呢?当然是希望每个样本的预测值尽可能与真实值相同不是吗,也就是我们希望似然函数达到最大,Let’s maximize likelihood.
我们可以看到以乘积的形式让值最大化有些困难,那么我们使得Log likelihood最大化,以加法的形式就很容易了:
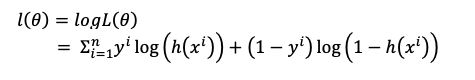
我们来看看Cousera里给出的Cost Function是什么样的:
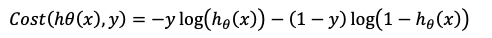
形式几乎和似然函数一样不是吗,它们的区别无非就是:当我们使用似然函数的时候,我们的目的就是为了让概率最大化,即最大化似然函数。当我们使用损失函数的时候,我们的目的就是为了让损失最小化,即最小化损失函数。
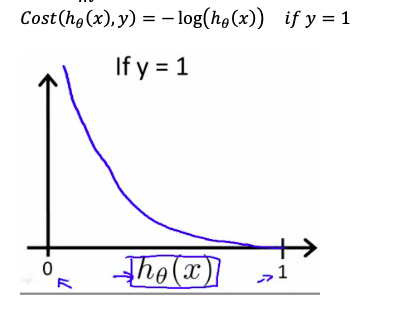
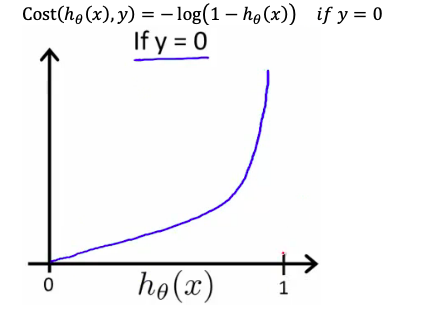
Gradient Descent for Cost Function
$\frac{\partial}{\partial \theta_j}J(\theta)=(h_\theta(x^i)-y^i)x_j$
$\theta_j:=\theta_j-\frac{\alpha}{m}\Sigma_{i=1}^{m}(h_\theta(x^i)-y^i)x_j$
Gradient Ascent for log likelihood
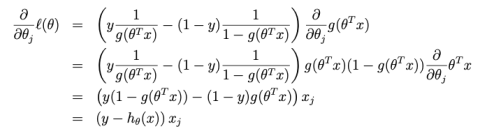
$\theta_j:=\theta_j+\alpha\Sigma_{i=1}^m(y^i-h_\theta(x^i))x_j^i$
本文由 Frank采用 署名 4.0 国际 (CC BY 4.0)许可
Machine Learning — 2021年4月20日
Made with ❤ and at Hangzhou.