ML-Cost Function
什么是Cost Function
顾名思义,Cost Function叫做损失函数,是用来衡量hypothesis(预测值)正确程度的函数。通常,损失函数会采用根据输入X所得的Hypothesis与真实目标值y的平均差值。
“Squared error function” or “Mean square error”
常见的损失函数:均方误差:$J(\theta_0,\theta_1)=\frac{1}{2m}\Sigma_{i=1}^m(h_\theta(x^i)-y^i)^2$
(此处只代表只存在一个特征的情况,所以参数为 $\theta_0$ , $\theta_1$)
你可能想知道为什么还有一个1/2,均值不应该是直接除以样本的数量m就好了吗。这里,1/2是为了方便计算和梯度下降。
怎么使用损失函数:
我们的目标就是为了让预测值尽可能接近真实值。所以相应的,当预测值hypothesis越接近真实值y,则误差越小,学习的效果越好。我们要做的是就是要让损失函数最小化。
其中 hypothesis 即 $h_\theta(x^i)=\theta^TX^i=\theta_0+\theta_1x^i_1+…+\theta_nx_n^i$
Crousera例子
下方的两个图分别是 $\theta_1=1$, $\theta_1=0.5$的情况,此处我们姑且让$\theta_0$为0,方便讨论。
PS: $\theta_0$ or bias为直线与y轴的截距,通过hypothesis function可知 $h_\theta(x) = \theta_0+\theta_1x$

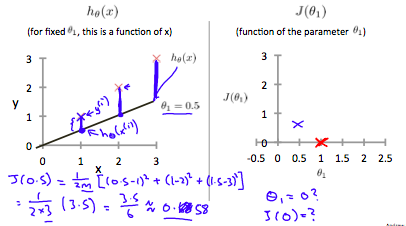
普遍的,当我们取遍所有 $\theta$ ,得到Cost Function
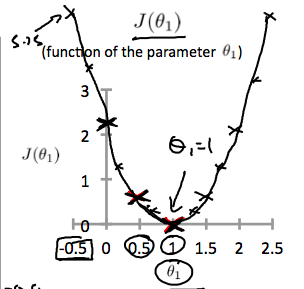
显然的,我们看到当 $\theta_1$ = 1时,得到一个全局最小值,他就是我们要的最优解。
例子2:
上面的例子只考虑到了 $\theta_1$ ,下面的例子将同时考虑 $\theta_0,\theta_1$
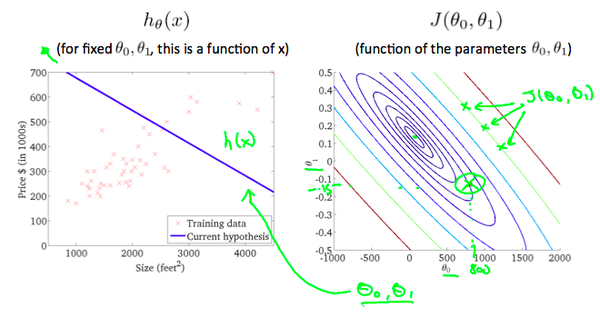
当同时考虑 $\theta_0,\theta_1$ 时,使用等高线图能更好的表示Cost Function。
同样的,我们的目标为使得J最小,从图中可以看出为椭圆的中心。
结束语
显然,要是我们一一列举 $\theta$,太麻烦了,而且不太现实。那么怎么才能以高效的方式得到最优解呢?梯度下降是一种方法。
本文由 Frank采用 署名 4.0 国际 (CC BY 4.0)许可
Machine Learning — 2021年4月20日
Made with ❤ and at Hangzhou.