ML-Classification
一种分类的方法是,结合之前的线性回归,然后让所有预测值比0.5大的值作为Positive,将小于0.5预测值的样本作为Negative(二分类)。然而,这种方法通常不是很好,因为我们的分类不一定是线性的。
为了解决这个问题,我们将引入新的Hypothesis function以满足 [公式] 。我们通过把 [公式] 带入到Logistic Function来满足这个需求。同时,我们还将引入Sigmoid Function。具体的表示形式为:
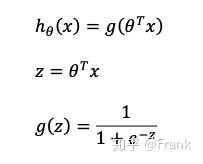
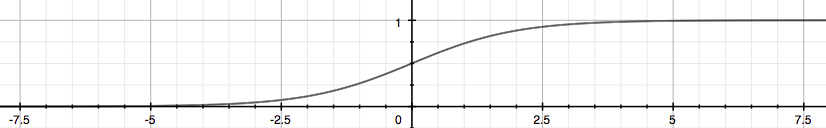
我们可以看到Sigmoid Function有很好的性质,它不仅使得所有的值落在0到1之间,而且,以0.5为分界线,把 [公式]分为大于0和小于0。
接下来我们详细讨论这个性质可以拿来做什么。为了让所有的预测值都为了离散的0或1值(暂时讨论二分类),我们可以通过如下方式转换Hypothesis function的输出
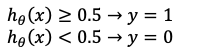
根据我们之前给出的Hypothesis function的表示形式,我们可以推出如下结论:
如果$z=\theta^Tx\ge0$那么$g(z)\ge0.5$于是y=1
反之如果$z=\theta^Tx<0$那么$g(z)<0.5$于是有y=0
那么我们可以很容易的推断出,二分类的Decision Boundary(决策边界,用于划分Positive和Negative)就是$\theta^Tx=0$
结束语:知道了Hypothesis Function,那么对于分类问题的Cost Function是啥呢?你可能会问,啥?为什么还要用新的Cost Function呢,直接用Linear regression的Square error function不好吗?有问题才要去解决不是吗,不然为什么要凭空再来一个Cost Function。是的接下来我们来研究为什么不使用Square error。
题外话:非常喜欢Andrew的授课方式,以问题带入,直到解决问题。我们人类不会凭空想象,一切基于需求。
本文由 Frank采用 署名 4.0 国际 (CC BY 4.0)许可
Machine Learning — 2021年4月20日
Made with ❤ and at Hangzhou.